

El aprendizaje automático y cómo crear música con IA
Inteligencia ArtificialLa inteligencia artificial lleva décadas con nosotros. Sin embargo, es ahora cuando estamos viendo su avance a pasos agigantados, ya que está adentrándose en sectores muy variados. Consiste en hacer que máquinas o programas de ordenador realicen tareas simulando, aunque sea de forma parcial, la inteligencia humana. Se le conoce como aprendizaje automático, y en este artículo, vamos a descubrirlo aplicado a la música.
El aprendizaje automático o machine learning es tan solo uno de tantos conceptos que forman parte de esta era tecnológica. Si quieres conocer todas las herramientas disponibles hoy en día para mejorar los procesos de las empresas y su productividad, inscríbete en el Máster en Business Analytics e IA.
¿Podemos usar el aprendizaje automático para crear música con IA?
Existen tareas que son tan humanas que parece muy difícil imaginar que un modelo de aprendizaje automático (o una IA, si abusamos un poco del lenguaje) sea capaz de hacerlas. Sin embargo, pensábamos lo mismo hace una década sobre lo que ahora nos parece normal. Del mismo modo, lo que todavía hoy nos resulta impensable, mañana será nuestra nueva realidad. Ahora le toca el turno a la posibilidad de crear música con IA.
¿Es posible confirmar que la IA tiene la capacidad de componer una canción, con su ritmo, música y letra? La respuesta corta es sí, es posible. Para probarlo, existen varios ejemplos muy interesantes y divertidos. Como Daddy's Car (Sony CLS Research Lab), considerada la primera composición basada en la Inteligencia Artificial, o The Golden Age, compuesta por la plataforma AIVA.
Pero esta es solo la respuesta rápida. Si entráramos en detalles, la explicación sería mucho más compleja. No obstante, vamos a romper una lanza a favor del ser humano. Si bien es cierto que hay modelos que componen canciones, todavía se encuentran a mucha distancia de lo que un compositor humano es capaz de hacer. Si no me creéis, os animo a echar un vistazo a este concurso de canciones creadas (con ayuda) de la IA.
El auge del aprendizaje automático y del deep learning
Crear canciones con IA es posible, sin entrar en detalles sobre su calidad o complejidad. Aunque de aquí a unos años es casi seguro que sus habilidades habrán mejorado con creces, lo que ahora nos atañe es de dónde venimos en cuanto a avances tecnológicos.
La respuesta la encontramos en conceptos como el Deep Learning o en el Machine Learning, que se traduce como aprendizaje automático. Los modelos basados en el primero son capaces de “realizar” tareas típicamente humanas con un rendimiento cercano, y a veces superior, al nuestro.
Digo “realizar” entre comillas porque, en realidad, el modelo se entrena para resolver un problema típico del aprendizaje automático, como un problema de clasificación, que podría ser de imágenes. Con esa clasificación, ya sea de estas o de detección de objetos, podemos desarrollar un software o aplicación que pueda, por ejemplo, controlar la entrada de las personas en un edificio basándose en la foto que tomamos de estas al entrar. Esta tarea, que ahora realizaría la persona encargada de la seguridad, ahora se puede automatizar con IA.
Y crear música con inteligencia artificial es solo un ejemplo entre todas las posibilidades y aplicaciones del machine learning que hay. Otros que ya hemos normalizado serían los asistentes virtuales que entienden lo que escribimos o decimos, recomendaciones personalizadas para contenido digital, etc.
Cómo entrenar un modelo para crear canciones con IA
Los modelos de aprendizaje automático se entrenan para resolver un problema de Secuencia a Secuencia, o “sequence to sequences” o “sec2sec” en inglés. La idea es que necesitamos un modelo que, dada una secuencia de entrada, por ejemplo, un texto en inglés, nos genere otra de salida adecuada. Esta podría ser la traducción del texto al castellano. De una forma más sencilla, hay una entrada que se le da al modelo y un resultado que es el que hay generado la máquina.
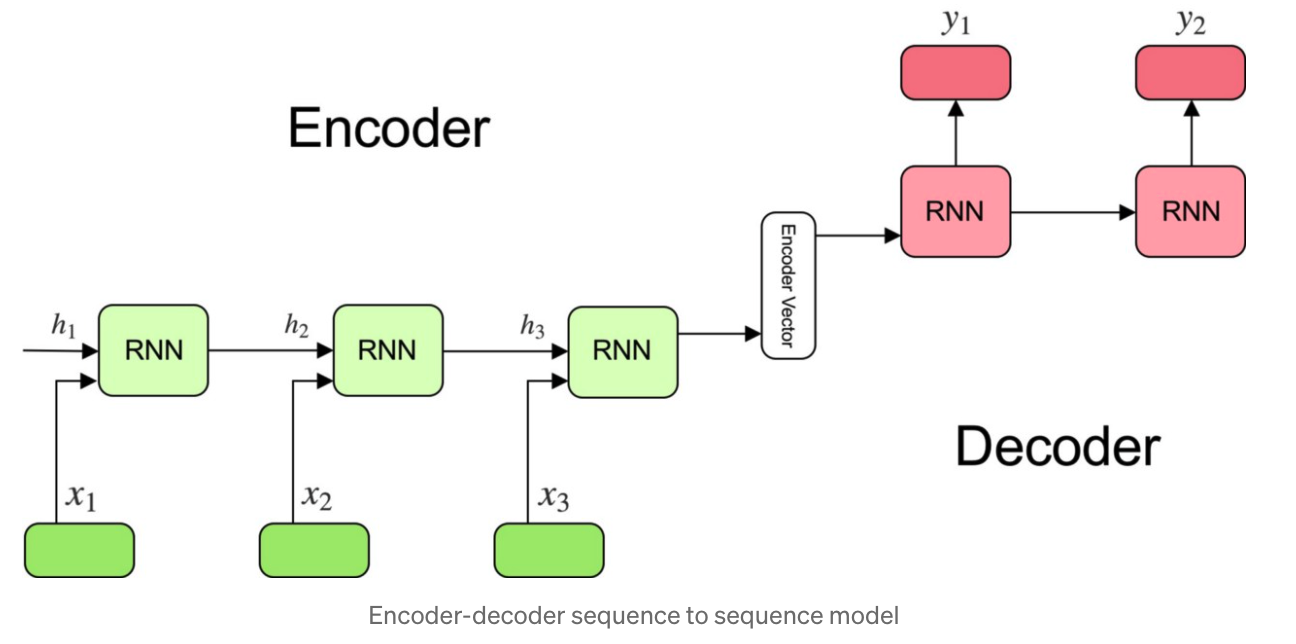
Fuente: https://towardsdatascience.com/understanding-encoder-decoder-sequence-to-sequence-model-679e04af4346
Estos modelos suelen tener dos componentes principales, un “Encoder” o codificador que transporta la secuencia de entrada a un estado intermedio (o espacio latente), y un “Decoder” que utiliza este estado intermedio para ir generando la secuencia de salida.
Con esta idea en mente, se podría intentar generar una secuencia de notas musicales que tuvieran sentido. Incluso sonidos MIDI. Un ejemplo de esta aproximación es Magenta, creada por el equipo de Tensorflow de Google. Si entráis en la plataforma, podréis crear vuestras propias composiciones, bien con la aplicación Magenta Studio o, si tenéis ganas, directamente en Python con este notebook.
El tipo de modelos encoder-decoder que utilizaron fue de la familia de los Autoencoders. Concretamente, Variational Auto Encoders. La idea actual es parecida. Un bloque encoder y otro decoder, pero entrenados de forma que el input y el output sea el mismo. Una vez entrenado el modelo, el Decoder se encargará de generar nuevas secuencias. Al modelo final lo bautizaron como MusicVAE.
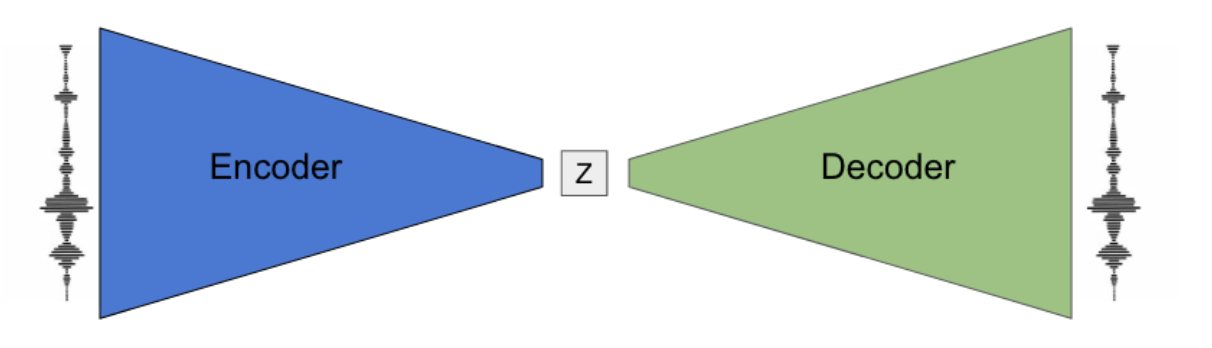
Fuente: https://magenta.tensorflow.org/music-vae
Como ejemplo interesante de la aplicación de este modelo, podéis ver cómo un DJ genera nuevas composiciones. Aunque también podéis crear nuevas canciones mientras escribís cómo os sentís en ese momento.
Interesante ¿verdad? Pues os recomiendo que también miréis NSynth, un sintetizador neuronal que también se encuentra bajo el proyecto Magenta. Según sus propios creadores:
“Es un algoritmo de aprendizaje automático que utiliza una red neuronal profunda para aprender las características de los sonidos y luego crear un sonido completamente nuevo basado en estas características.”
No obstante, existen otras aproximaciones más avanzadas de aprendizaje automático. Estas también quieren trabajar la armonía, la sonoridad de los instrumentos, la generación de voz humana y otros aspectos importantes en una composición.
OpenAI entrenó hace un tiempo un primer intento llamado MuseNet, donde los sonidos generados eran MIDI. Espectacular, pero limitada. Poco después entregó una nueva red profunda capaz de generar música de muchos formatos diferentes. A este modelo lo llamaron Jukebox. En este caso, la secuencia de entrada del modelo no son sonidos MIDI, sino sonidos en bruto. Esto le da mucha más riqueza al sonido generado.
Y para terminar, no podía faltar MusicGen. Es una solución innovadora en la industria musical que combina técnicas avanzadas de inteligencia artificial con la creatividad humana. El resultado es música original instantánea y personalizada. Se basa también en algoritmos de aprendizaje automático, con los que analiza patrones musicales, estilos y preferencias del usuario para componer piezas únicas que se adaptan perfectamente a cada situación. Cuenta con múltiples estilos musicales y permite a los usuarios interactuar y refinar la música que se genera en tiempo real.
¿Ganas de más? ¿Quieres más detalles? Aquí tenéis un excelente, y también muy técnico, enlace sobre la generación de música con aprendizaje automático.
Conclusión
Hemos visto que los modelos generativos están progresando a pasos agigantados en campos tan humanos como la composición musical. ¿Eso significa que ya no somos necesarios? ¡No, ni mucho menos! Las tareas humanas complejas, como la composición musical, escribir un poema o un libro, están aún lejos del alcance de la inteligencia artificial actual.
Por ahora, los modelos generan composiciones aceptables y técnicamente correctas. Pero no son capaces de añadirles la emoción que podemos crear los humanos. Sin embargo, y precisamente porque estamos progresando a mucha velocidad, hay que mantenerse pendientes para conocer los nuevos logros del aprendizaje automático.


