

Explorando el Potencial de la Inteligencia Artificial Multimodal
DataContexto
A la hora de interpretar la realidad del mundo que nos rodea utilizamos al mismo tiempo y de manera coordinada todos nuestros sentidos. Por ejemplo, cuando paseamos por el campo, nuestros ojos perciben el entorno e identifican distintos elementos como caminos o árboles, nuestros oídos capturan sonidos como el de los pájaros, y nuestro olfato detecta el aroma de las flores, y mediante el tacto podemos sentir la textura de las hojas. Esta integración sensorial nos permite experimentar y comprender plenamente nuestro entorno.
Cuando hablamos de sistemas de inteligencia artificial (IA) que automatizan tareas, procesan documentos, o detectan objetos en imágenes, por citar algunos ejemplos, lo habitual es que estos sistemas estos sistemas sean cada vez más y más precisos en una tarea, pero siendo capaces de trabajar únicamente con un tipo de información.
Más recientemente, y muy relacionado con los avances en IA Generativa, esta tendencia ha cambiado. Llevamos ya varios años donde los modelos de IA son capaces de procesar distintos modos de información. Por ejemplo, modelos como DALL·E 3 interpretan la descripción que un usuario realiza de una escena en lenguaje natural y este genera una imagen de acuerdo con dicha descripción. El modelo es capaz de entender el lenguaje, y conectar los conceptos que interpreta del mensaje con los que genera en la imagen a su salida.

Imagen generada con DALL·E 3 con el siguiente prompt [1].
A potato king wearing majestic crowns, sitting on thrones, overseeing their vast potato kingdom filled with potato subjects and potato castles.
A esta capacidad de trabajar con distintos modos de información se la conoce como multimodalidad.
Multimodalidad
Demos un ejemplo para entender esto. Si hablamos dos idiomas, como el español o el inglés, decimos que somos bilingües. Pero si empleamos simultáneamente el habla junto a los signos, nos referimos a comunicación bimodal, ya que empleamos dos modos de comunicarnos.
En el ámbito de la IA también existe el concepto de multimodalidad, y hace referencia a la capacidad de estos sistemas y modelos de procesar y entender datos de diferentes modalidades como pueden ser texto, imágenes, audio, o vídeo.
Esto es posible porque los modelos de IA, cuando codifican la información que reciben en vectores. Por ejemplo, una imagen de un coche azul y otra de un coche rojo tendrán vectores muy similares al corresponderse a imágenes parecidas.
Las IA multimodales son capaces de codificar en vectores la información de diferentes modos de información al mismo tiempo. De esta manera, si observan un coche en una imagen, o si reciben la palabra “coche”, codificarán ambos datos con un vector muy similar. Ambos vectores coexistirán en el mismo espacio vectorial, de forma que el modelo de IA los tratará de manera intercambiable, entendiendo que hacen referencia a la misma realidad.
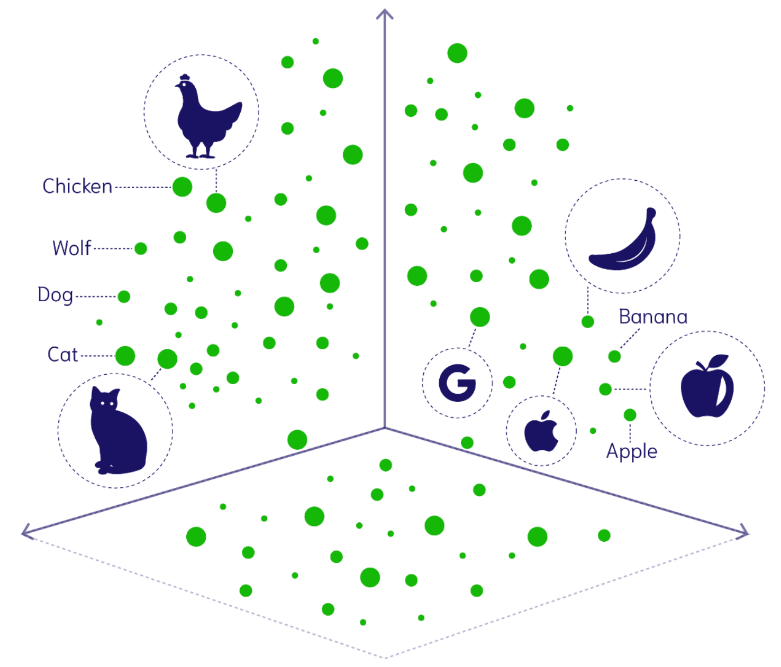
Representación gráfica de un espacio vectorial donde aparece codificados tanto textos como imágenes [2].
Esto permite que los modelos de IA multimodal resuelvan problemas como buscar imágenes mediante texto, buscar vídeos con imágenes, generar una descripción a partir de una imagen, o componer música tomando como referencia un texto.
Pero, ¿cuál es el estado actual de los modelos de IA multimodal? Veámoslo con dos ejemplos.
SORA
El ejemplo más reciente -a fecha de escritura de este artículo- es SORA, el último modelo de IA desarrollado por OpenAI. De manera similar a DALL·E 3, que permite generar imágenes a partir de texto, SORA es capaz de crear vídeos tomando como punto partida una descripción en lenguaje natural de lo que el usuario desea recrear. Si bien no es el primer modelo que es capaz de convertir texto a vídeo, hoy en día es el que mejores resultados aparentemente devuelve.
Esta captura extraída de uno de los vídeos de muestra publicados en la web de OpenAI [3] es solo un ejemplo del potencial de esta IA.

Frame de un vídeo generado por SORA con el prompt:
A stylish woman walks down a Tokyo street filled with warm glowing neon and animated city signage. She wears a black leather jacket, a long red dress, and black boots, and carries a black purse. She wears sunglasses and red lipstick. She walks confidently and casually. The street is damp and reflective, creating a mirror effect of the colorful lights. Many pedestrians walk about.
ImageBind
Meta AI es sin duda un actor clave en el ecosistema de la IA, impulsando no solo la creación de distintos modelos, como puede ser Llama-2 en el contexto de los grandes modelos de lenguaje (LLM), sino desarrollando nuevos sistemas capaces de codificar la realidad y el contexto que observan trabajando con múltiples modos de información al mismo tiempo.
Un ejemplo reciente es ImageBind, IA desarrollada por investigadores de Meta AI capaz de trabajar con hasta seis modos al mismo tiempo. Reconoce y relaciona información entre imágenes, vídeo, audio, texto, profundidad en la imagen, y unidades de medición inercial (IMU).
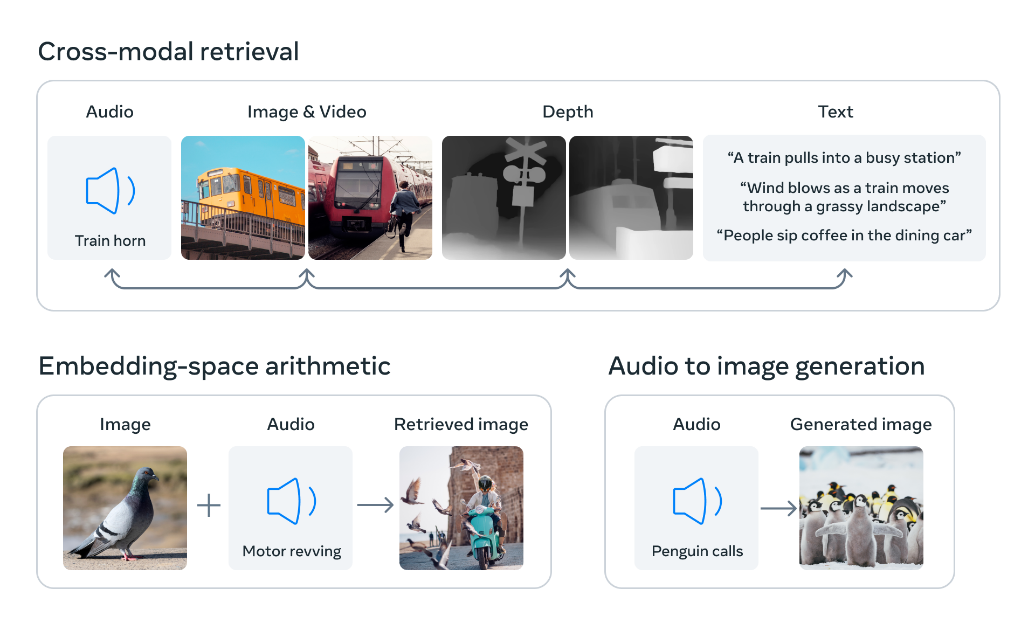
Representación gráfica de como ImageBind es capaz de codificar y relacionar información de distintos modos de información al mismo tiempo [3].
Conclusiones
Las IA multimodales son revolucionarias porque combinan diferentes modalidades de datos, como texto, imagen, audio y/o vídeo, para realizar tareas de manera más compleja y natural.
Esto permite una comprensión más completa del contexto y una interacción más natural con los usuarios. Al poder entender y generar contenido en múltiples modalidades, estas IA tienen aplicaciones en un amplio número de campos y sectores.
Su capacidad para procesar información de manera holística las hace extremadamente útiles para resolver problemas complejos y mejorar la interacción humano-máquina.
La clave de todos estos modelos no es únicamente la calidad del contenido que generan -sin duda sorprendente- sino su capacidad de interpretar la realidad de los datos con los que trabajan, y de encontrar relaciones entre esos datos.
Como resumen, las IA multimodales representan un avance significativo en el campo de la IA al proporcionar una comprensión más profunda y rica del mundo, lo que resulta en aplicaciones prácticas que mejoran la vida cotidiana en una variedad de contextos.
Referencias
[1] https://openai.com/dall-e-3
[2] https://weaviate.io/blog/multimodal-models
[4] https://ai.meta.com/blog/imagebind-six-modalities-binding-ai/
Carlos Rodríguez Abellán
Lead NLP Engineer en Fujitsu
